“When in doubt:
blkdiscard,talhelper, a goodtaskfile, and a mug of coffee…or in my case Musashi Energy - lemonade”
Why I nuked the cluster
I wanted to simplify how Flux applies applications. Historically the top-level Kustomize for every workload lived inside flux-system, which meant lots of cross-namespace references and annoyingly long paths. The plan was to move each app’s Flux Kustomization into the namespace it actually manages so that kubernetes/apps/<namespace>/<app>/ks.yaml is the single source of truth.
That migration touched everything that rolls pods, including storage. Rook-Ceph saw the new manifests, decided that it needed to reconcile, and immediately tripped over the existing OSD data on disk. The net result: the operator kept trying to reformat disks that still held live block devices, the rollout failed in a messy state, and the cluster stopped scheduling anything critical. At that point it was faster (and safer) to pave the nodes and start clean than it was to try to coax Rook back to health while half the controllers were stuck.
Info
I’m assuming you are also doing DR, so you will have the existing CLI tools installed
Wiping the nodes
I keep a USB stick with ubuntu-24.04.3-desktop-amd64.iso around for this exact situation. Live-booting into “Try Ubuntu” gives me a predictable environment, modern nvme-cli, and a desktop for sanity checks. On each node (Stanton-01/02/03) I confirmed the disks with lsblk:
|
|
My Talos install lives on two NVMe devices:
nvme1n1 (990 GB)
- The TalosOS Disk
- Where Open EBS hostpath PVCs live
nvme0n1 (1.75 TB)
- Dedicated RookCeph Disk
- Runs on a Thunderbolt ring network
Once confirmed, I zeroed the flash translation layer and wiped the labels:
|
|
Wiping Disks
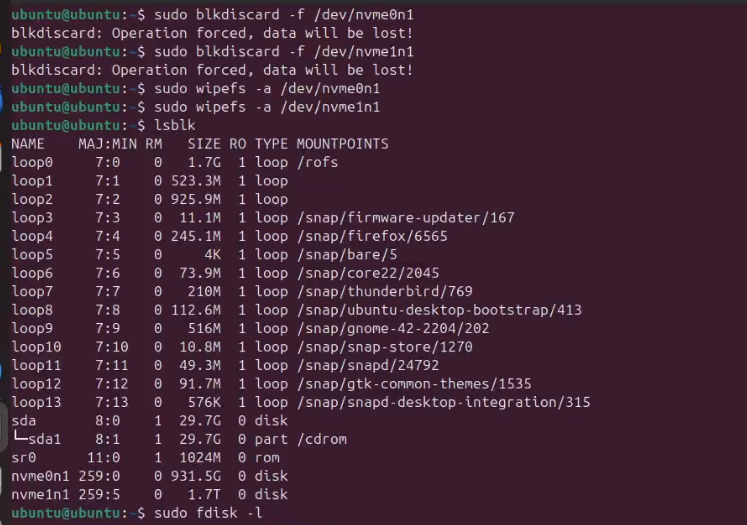
Then I ran fdisk to take a look at the NVMEs
|
|
Running fdisk-l

blkdiscard is the important bit for Rook. It makes sure the SSD firmware really forgets the previous partitions, which prevents Ceph from thinking an OSD is already provisioned the next time it boots. A final lsblk/fdisk -l confirmed that both drives were back to “disk only” with no partitions or filesystems.
What we are looking to see here is that neither disk has any partitions on it (which we do see). After all the machines are wiped, we are ready to move on.
Power down the machines, remove the Ubuntu media and prep the Talos media.
I should note. I have a dedicated JetKVM per Talos Node so I can easily view what the machine is doing, from the browser of my desktop computer. No need for KB/Mouse/Monitor on the actual machines. In addition, I run the JetKVM DC Power Control Extension so I can remotely power on and off the machines.
Refreshing the Talos media
All three nodes share the same Talos schematic (d009fe7b4f1bcd11a45d6ffd17e59921b0a33bc437eebb53cffb9a5b3b9e2992) which is baked into my existing talosconfig. That meant I could download the matching ISO straight from the factory and know it would have the right kernel modules, Thunderbolt NIC support, and SecureBoot bits:
|
|
I still write it out with Rufus on a Windows machine because it’s the quickest way to prepare three bootable USB sticks. Live-boot Talos, point it at the controller VIP, and wait for maintenance mode.
For this I have 3 Identical Tesla 128GB USB Sticks (Two of which came out of our cars, the 3rd I grabbed from FB Marketplace)

talhelper, Task, and my bootstrap workflow
Everything from this point lives in gavinmcfall/home-ops, which keeps Talos, Flux, and the apps in Git. Two files matter for bootstrap:
kubernetes/bootstrap/talos/talconfig.yaml– the talhelper definition of the cluster (VIP10.90.3.100, Thunderbolt cross-connects, bonded Intel NICs, etc.)..taskfiles/Talos/Taskfile.yaml– wraps the talhelper commands so I don’t fat-finger args.
The talos:bootstrap task is essentially:
|
|
That installs Talos to all three NVMe devices, boots them into the control plane, then waits for etcd to converge. The follow-up install-helm-apps task runs kubernetes/bootstrap/helmfile.yaml, which deploys the CRDs Cilium needs, Cilium itself, CoreDNS, and Spegel so talosctl can start reporting node health correctly.
Because the Talos VIP and Thunderbolt-only links are described directly inside talconfig.yaml, there is nothing manual to do after the ISO is written. The KubePrism SAN, bonded NIC configuration, and node-specific Thunderbolt routes are reapplied automatically. That’s the magic of keeping talconfig and the cluster secrets in Git.
Doing a dry run
Before I actually pipe talhelper gencommand apply into bash, I like to rehearse the entire sequence so I know Talos will accept the configs:
|
|
1. Generate configs (safe, local files only)
|
|
Output:
|
|
2. Preview the apply/bootstrap commands
|
|
Output:
|
|
3. Preview bootstrap command
|
|
Output:
|
|
This is expected to only show one node, as Bootstrap initializes the cluster on a single node (stanton-01 in this case) and then the other nodes join it
4. Dry-run each node
|
|
Output:
|
|
If like me you just swap the IP address when typing the command again and forget to swap the file name…
e.g. talosctl apply-config --insecure --nodes 10.90.3.102 --file clusterconfig/home-kubernetes-stanton-01.yaml --dry-run
You will get an error:
|
|
Make sure if you are going to be lazy, you are also accurate — the dry run is there to catch mistakes before Talos ever touches a disk.
talhelper genconfig prints which files were created, while the gencommand invocations show the exact talosctl commands that task talos:bootstrap is about to execute. The last step validates that each node is sitting in maintenance mode and that Talos can match the disk selector defined for that specific host. Once everything looks good it’s time to let the task rip.
Install Time

#ifYouKnowYouKnow
The entire process took 6 minutes from the time I typed task talos:bootstrap to the time it was done.
You will see connection errors and lots of other “scary” looking things, this is just because this process polls for things that are not “up” yet. Just wait, go make a drink, have a cookie.
Running task talos:bootstrap
|
|
task runs every command defined in .taskfiles/Talos/Taskfile.yaml: it (re)generates Talos secrets if they’re missing, renders configs, applies them to each node, performs the one-time bootstrap on stanton-01, downloads the kubeconfig, and applies the bootstrap Helm apps (Cilium/CoreDNS/Spegel). If something fails midway I can rerun the task and it will pick up where it left off.
Output:
|
|
Can I see and talk to the cluster?
In your terminal, run:
|
|
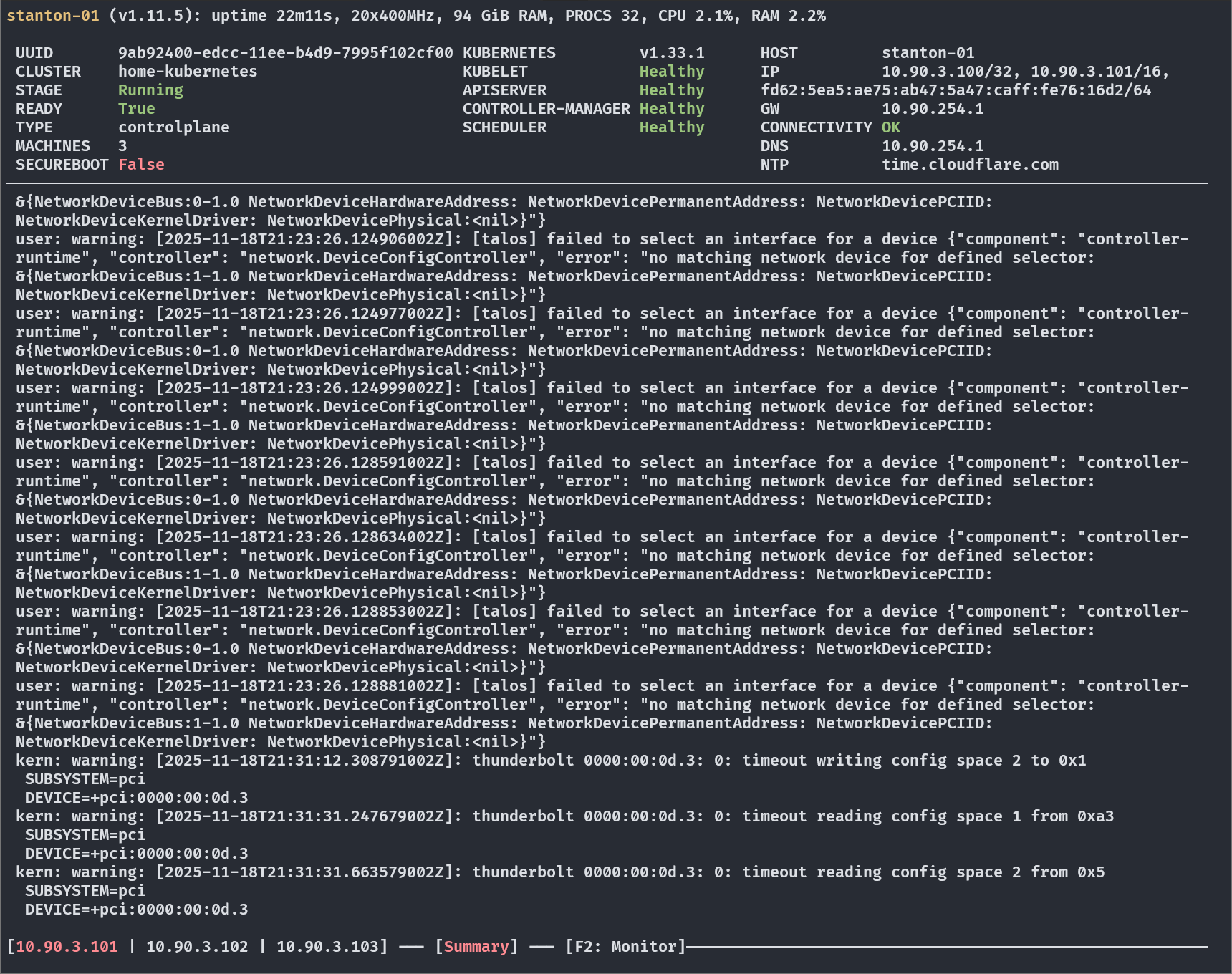
You can use your keyboard’s left and right arrows to cycle through the nodes. In addition I run k9s and can run this to see my cluster
|
|
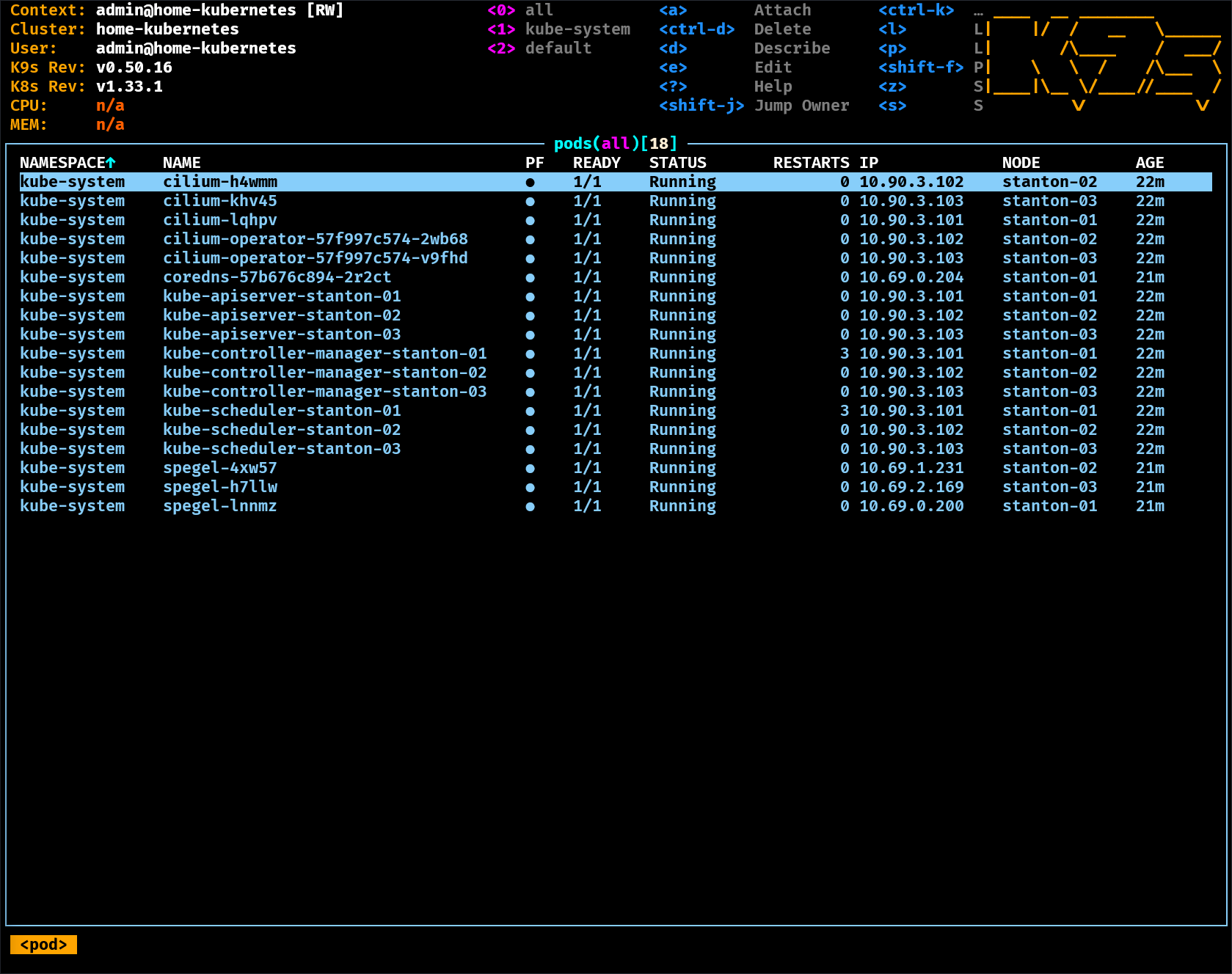
The default page takes me to a view of all pods across all namespaces
Holding Shift and pressing ; will type a : which opens the k9s menu.
From here you can type nodes and press enter to see the nodes

Rehydrating GitOps state
Before I do this next step I want to make sure the majority of my cluster is “Off” in Git. My repo layout is
home-ops/kubernetes/apps/<namespace>
Inside each namespace folder is a top-level kustomization.yaml
e.g.
|
|
You can see here I have commented out everything except the creation of the namespace. This means it won’t initially deploy this when I task flux:bootstrap
I did this for every namespace except
- cert-manager
- external-secrets
- flux-system
- kube-system
- network
- openebs-system
- volsync-system
Once Talos hands back a kubeconfig (stored at kubernetes/bootstrap/talos/clusterconfig/talosconfig), Flux gets bootstrapped with another task:
|
|
Output:
|
|
That command:
- Applies the manifests under
kubernetes/bootstrap/flux, including the deploy key secret. - Decrypts and applies
flux/vars/cluster-secrets.sops.yaml. - Applies cluster settings and Kustomizations per namespace (
kubernetes/apps/<namespace>/<app>).
Disaster…Kinda
Because I am now cut over to Envoy Gateway and not ingress-nginx I am missing the Gateway CRDs because Cilium does not install them (I’m not using Cilium for Gateway API, I’m using Envoy)
Now I could just kubectl apply -f https://github.com/kubernetes-sigs/gateway-api/releases/download/v1.2.0/standard-install.yaml and solve the problem… But that’s not IAC
So, I created a new folder home-ops/kubernetes/apps/network/gateway-api
|
|
That kustomization.yaml is fairly simple. Its job is to install the Gateway API CRDs
|
|
owever, I need these installed before Envoy so Inkubernetes/apps/network/envoy-gateway/ks.yaml I had to add a dependsOn:
|
|
Now this comes up first, then Envoy.
Sometimes things come up a little out of order, especially where CRDs are concerned. best bet is to check things and reconcile if needed. Example
envoy-gateway came up (the main Helm Release and installed the CRDs) but the dry run failed for envoy-gateway-config
All I had to do is:
|
|
And the Ks Applied Revision and the rest of Envoy rolled out
Rook-Ceph DR Recovery: Why It Wouldn’t Start
Issue 1: Cleanup Policy Blocking Orchestration
Symptom: Operator logs showed:
|
|
Cause: The CephCluster spec had cleanupPolicy.confirmation: yes-really-destroy-data set. When this field is present, Rook interprets it as “this cluster is being deleted” and skips all orchestration entirely. Fix: Removed from helmrelease.yaml:
- confirmation: yes-really-destroy-data
- wipeDevicesFromOtherClusters: true
Since the HelmRelease was stuck reinstalling, we also patched directly:
|
|
Issue 2: OSD Network Configuration Failure
Symptom: OSD pods in CrashLoopBackOff with:
|
|
Cause: The Ceph cluster was configured to use 169.254.255.0/24 (Thunderbolt mesh) for cluster traffic, but the Thunderbolt interfaces weren’t up - the kernel showed timeout errors trying to communicate with the Thunderbolt controller. Fix:
- Replugged the Thunderbolt cables between nodes
- Verified interfaces came up with correct IPs (169.254.255.101/32)
- Temporarily patched cluster network to use main network while Thunderbolt was down:
|
|
Lessons Learned
cleanupPolicy.confirmationis a deletion flag - Only set it when you actually want to destroy the cluster- Check physical connectivity - Thunderbolt timeouts in dmesg indicate cable/connection issues
- Network config must match available interfaces - OSDs can’t start if they can’t find an IP in the configured cluster network range
The layout change that started this mess is still worth doing, so I’m re-introducing it carefully:
- Each namespace owns its Flux
Kustomization(ks.yamlin the namespace folder). - Reconciles happen namespace-by-namespace with
task flux:apply path=rook-ceph/cluster ns=rook-ceph. - Critical infrastructure (Talos bootstrap Helm releases + Flux) never reference manifests outside their namespace so I can fence blast-radius.
Once Flux is healthy I let VolSync and CloudNativePG pull data back from object storage, which rebuilds PVCs long before Rook redeploys fresh OSDs.
Next Steps
Roll out Database Namespace
My Database Namespace contains
- Cloudnative PG (Postgres)
- Dragonfly DB (Redis) - Currently blocking the rollout of OAuth2Proxy which depends on this
- Maria DB (My SQL)
- Mosquitto (MQTT Message Broker)
For this, I will edit the kustomization.yaml in the Database namespace to uncomment the paths
|
|
Postgres restore
In Backblaze I have my Postgres Backups
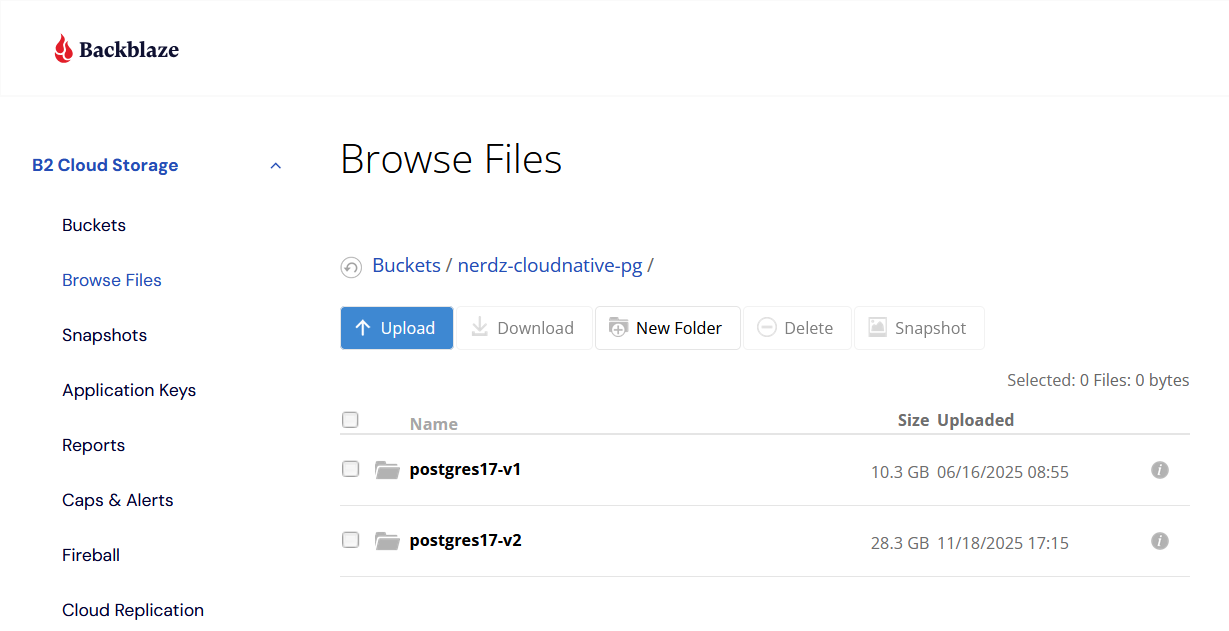
and in my Cloudnative Postgres cluster config I have my restore settings: kubernetes/apps/database/cloudnative-pg/cluster17/cluster17.yaml
|
|
This tells Postgres to grab the data from postgres17-v2 in backblaze and to build a new cluster called postgres17-v3 and sync that to backblaze.
MariaDB: when charts won’t behave
MariaDB should have been the easy part. The upgrade from Bitnami’s 22.x chart to 23.x surfaced two separate gotchas:
- Bitnami yanked the old
12.0.2-debian-12-r0image tags, so the kubelet couldn’t pull the default container anymore. - The new chart force-enables FIPS templating and renders two
envsections in the mysqld-exporter sidecar whenever metrics are on, which makes Flux’s post-render stage blow up before anything gets applied.
How I pulled it back:
- Temporarily pinned the MariaDB, volume-permissions, and mysqld-exporter containers to known-good digests so the cluster stayed alive while I figured out 23.x.
- Added
global.defaultFips: "off"plus explicit"off"overrides forprimary,volumePermissions, andmetricsFIPS blocks so Helm would render the new manifests. - Disabled the chart’s built-in metrics and stood up my own exporter Deployment + Service + ServiceMonitor (now in
kubernetes/apps/observability/exporters/mariadb-exporter). It still runs in thedatabasenamespace, readsmariadb-secret, and Prometheus keeps scraping through the ServiceMonitor. - Once everything was committed, I suspended/resumed the HelmRelease to clear Flux’s stuck rollout and let the StatefulSet recreate cleanly.
It’s not glamorous, but it gets MariaDB onto chart 23.2.4 without losing metrics, and every moving piece is now in Git so the next rebuild will just be another task flux:apply.
Continuation - More namespaces coming online
Now that MariaDB was sorted I moved on to enabling the next lot of namespaces
- Observability (exporters, gatus, grafana, kromgo, kube-prometheus-stack, loki, network-ups-tools, promtail, redis insights and unpoller)
- Then the security namespace (pocket-id)
- This allowed me to kick the oauth2proxy pods which were crashlooping and get them running again
- except… :sob:
oauth2-proxy Hairpin NAT and the Gateway API Version Maze
With pocket-id running I expected oauth2-proxy to come up cleanly. Instead all three replicas crashed with OIDC discovery timeouts trying to reach id.${SECRET_DOMAIN}. The culprit: hairpin NAT. Pods on the same node as the external gateway couldn’t reach its LoadBalancer IP (10.90.3.201) and curl just hung.
The classic fix is split-horizon DNS—have CoreDNS forward queries for your domain to an internal resolver that returns ClusterIPs instead of the external gateway. I already had k8s-gateway deployed at 10.96.100.130, so I added a server block to CoreDNS:
|
|
That should have been the end of it, but k8s-gateway refused to serve queries:
|
|
k8s-gateway v0.4.0 hardcodes a watch on v1alpha2.GRPCRoute, but I was running Gateway API v1.2.0 which only ships v1.GRPCRoute. The experimental bundle doesn’t help—v1alpha2 was removed in v1.1.0+.
The fix required threading a needle between multiple version requirements:
- Envoy Gateway v1.6.0 needs
BackendTLSPolicyat API versionv1, which only exists in Gateway API ≥v1.4.0 - k8s-gateway v0.4.0 needs
v1alpha2.GRPCRoute, which was removed in Gateway API v1.1.0+
The solution is to use Gateway API v1.4.0 experimental (for BackendTLSPolicy v1) and patch the GRPCRoute CRD to add v1alpha2 back. See the “Permanent Fix: JSON Patch for v1alpha2.GRPCRoute” section below for the full solution.
But I wasn’t done. k8s-gateway was only watching Ingress and Service resources. pocket-id uses Gateway API HTTPRoutes for ingress, so k8s-gateway had no idea id.${SECRET_DOMAIN} existed:
|
|
One more gotcha: deleting and recreating the Gateway API CRDs wiped out all existing HTTPRoute resources, and Helm didn’t know to recreate them since the release checksum hadn’t changed. I had to manually reapply from the helm manifest:
|
|
After all that, DNS finally resolved:
|
|
And oauth2-proxy came up healthy:
|
|
Gateway API Version Hell: BackendTLSPolicy and WebSocket Drama
Just when I thought I was done, external services started failing. TrueNAS and Unifi were returning 400 Bad Request errors on WebSocket connections. The UI would load, but any real-time features (shell, charts, live updates) were dead.
The Problem
Envoy Gateway v1.6.0 expects BackendTLSPolicy at API version gateway.networking.k8s.io/v1, but Gateway API v1.1.0 experimental only ships v1alpha3. Meanwhile, k8s-gateway v0.4.0 hardcodes watching for v1alpha2.GRPCRoute which doesn’t exist in newer Gateway API releases.
The operator logs were clear:
|
|
This meant Envoy wasn’t applying TLS settings to the backends at all.
The Fix (and the Trap)
Upgrading Gateway API to v1.4.0 experimental brought in BackendTLSPolicy v1 (see the full kustomization.yaml with the GRPCRoute JSON patch in the “Permanent Fix” section below).
Updated the BackendTLSPolicy resources from v1alpha3 to v1, removed the namespace field from targetRefs (v1 doesn’t have it), and removed sectionName to apply TLS to all service ports.
But then WebSockets broke. I spent an hour chasing the wrong fix—removing useClientProtocol: true thinking it was sending HTTP/2 to HTTP/1.1-only backends. Wrong move.
The original working config (pre-wipe) had:
|
|
This setting is essential for WebSocket support. When a client initiates an HTTP/1.1 WebSocket upgrade, Envoy needs to forward that same protocol to the backend. Removing it caused Envoy to use its default protocol (HTTP/2 with ALPN), which the backends rejected.
WebSocket support is handled by useClientProtocol: true in the BackendTrafficPolicy—it allows Envoy to forward the client’s HTTP/1.1 upgrade request using the same protocol.
Permanent Fix: JSON Patch for v1alpha2.GRPCRoute
After fighting this multiple times (every Flux reconciliation would remove the manually-applied CRD), I finally found a permanent solution. The problem is that k8s-gateway v0.4.0 hardcodes a watch on v1alpha2.GRPCRoute, but Gateway API v1.1.0+ only ships v1.GRPCRoute.
You can’t just add the old CRD as a separate resource—Kustomize will fail with “may not add resource with an already registered id” because both define the same CRD name.
The fix is to use a JSON patch to append v1alpha2 as an additional version to the existing GRPCRoute CRD:
|
|
This approach:
- Pulls Gateway API v1.4.0 experimental (with v1.GRPCRoute and BackendTLSPolicy v1)
- Uses
op: addwithpath: /spec/versions/-to append v1alpha2 to the versions array - Keeps v1 as the storage version while serving v1alpha2 for k8s-gateway
Now when Flux reconciles, k8s-gateway finds its required v1alpha2.GRPCRoute and stops complaining. No more manual patching after reconciliations.
Lessons learned:
- Gateway API version compatibility is a minefield. k8s-gateway, Envoy Gateway, and external-dns all have different requirements. Pin to v1.4.0 experimental for BackendTLSPolicy v1 support with Envoy Gateway v1.6.0.
- Always add HTTPRoute to k8s-gateway’s
watchedResourcesif you’re using Gateway API for ingress. - CRD deletions cascade to all CR instances. After recreating CRDs, you need to force Helm to reapply resources even if the chart version hasn’t changed.
- Don’t remove
useClientProtocol: truefrom BackendTrafficPolicy – it’s required for WebSocket connections to work properly. When in doubt, check the original working config before making changes. - Use JSON patches to add CRD versions – when you need to support multiple API versions in a single CRD, use Kustomize JSON patches with
op: addto append versions without replacing the original.
Hairpin NAT and Cilium socketLB
After all the Gateway API CRD drama, I hit another wall: pods couldn’t reach services on the external gateway. BookStack’s OIDC login to PocketID was timing out with cURL error 6: Could not resolve host: id.nerdz.cloud.
The symptoms were confusing:
- DNS resolved correctly via k8s-gateway (returning the LoadBalancer IP)
- The pod could reach the service directly via ClusterIP
- But any attempt to curl the LoadBalancer IP from inside the cluster timed out
This is the classic hairpin NAT problem. With ingress-nginx, this worked because it runs with hostNetwork: true, so traffic never goes through the LoadBalancer service from inside the cluster. But Envoy Gateway deploys proxies as regular pods without hostNetwork, so internal traffic trying to reach the LoadBalancer IP gets stuck.
The fix? Enable Cilium’s socketLB. This allows pods to reach LoadBalancer IPs directly by doing socket-level interception:
|
|
Before this change, bpf-lb-sock was false in the cilium-config ConfigMap. After enabling it, pods can reach any LoadBalancer IP in the cluster, including the external gateway where PocketID lives.
I also added an internal HTTPRoute to pocket-id as a belt-and-suspenders approach, so k8s-gateway returns both the internal and external gateway IPs. But the real fix was enabling socketLB.
Lesson learned: If you’re using Cilium with Envoy Gateway (or any ingress that doesn’t use hostNetwork), you need socketLB.enabled: true for pod-to-LoadBalancer connectivity.
Rook Ceph: clearing the “too many PGs per OSD” alert
Even on the fresh Talos rebuild, Ceph immediately threw HEALTH_WARN too many PGs per OSD (265 > max 250). With only three NVMe-backed OSDs online, the default PG soft limit is tight, so any extra pools tip it over. The culprit was the bootstrap RGW realm (default) that Rook creates every time, even if you never intend to use it.
What I did:
-
Confirmed the warning was PG-related –
kubectl -n rook-ceph exec deploy/rook-ceph-tools -- ceph statusshowed 265 PGs spread across 15 pools, all OSDs healthy. -
Inspected pool usage –
ceph df detailrevealeddefault.rgw.(log|control|meta)sucking up 96 PGs despite having zero data. -
Verified the realm was unused –
radosgw-admin realm/zonegroup/zone listonly reportedceph-objectstoreas active; the olddefaultentries had no buckets or users (radosgw-admin bucket list --rgw-zone=defaultreturned[]). -
Deleted the bootstrap realm stack – removed the
defaultzonegroup + zone, ranradosgw-admin period update --commit, then dropped the three empty pools with:1 2 3ceph osd pool rm default.rgw.log default.rgw.log --yes-i-really-really-mean-it ceph osd pool rm default.rgw.control default.rgw.control --yes-i-really-really-mean-it ceph osd pool rm default.rgw.meta default.rgw.meta --yes-i-really-really-mean-it -
Rechecked cluster health – PG count fell to 169 and
ceph statusflipped back toHEALTH_OK.
Lesson learned: after every fresh Rook install, delete the unused default RGW realm or scale up OSDs before enabling your workloads. Otherwise Ceph wastes PGs on pools you don’t even mount, and you get an avoidable health warning the moment the cluster comes online.
I’m still in the middle of rebuilding, but wiping the nodes and re-running the Talos + Flux bootstrap took under an hour once the ISO was ready. The longest part was downloading backups and letting VolSync rehydrate PVCs. If you ever reach the point where Rook is fighting ghost disks, don’t be afraid to pave the nodes. Talos makes the clean-room reinstall repeatable, and GitOps brings all of the workloads back on autopilot.
Discovering ImageVolume: OCI images as read-only config volumes
While getting qbittorrent running, I noticed it was using something I didn’t know existed: the type: image persistence option in bjw-s’s app-template. It lets you mount an OCI image directly as a read-only volume—perfect for bundling binaries or config without maintaining separate ConfigMaps or init containers.
The qbittorrent helmrelease mounts qbrr (a torrent reannounce tool) this way:
|
|
This pulls the OCI image and mounts its filesystem as a read-only volume—qbittorrent gets access to the qbrr binary without needing an init container to copy it over. The catch? It requires the Kubernetes ImageVolume feature gate, which is alpha and disabled by default.
Enabling ImageVolume on Talos
Enabling a Kubernetes feature gate on Talos means patching both the kubelet (on all nodes) and the API server (on control plane nodes). I followed MASTERBLASTER’s pattern from their home-ops repo.
Step 1: Create the controller patch for the API server
File: kubernetes/bootstrap/talos/patches/controller/feature-gates.yaml
|
|
Step 2: Update the kubelet patch
Added to the existing kubernetes/bootstrap/talos/patches/global/kubelet.yaml:
|
|
Step 3: Reference the new patch in talconfig.yaml
Added "@./patches/controller/feature-gates.yaml" to the controlPlane patches list.
Rolling out the change safely
Talos machineconfig changes can be risky—a bad config can brick your nodes. I took a cautious approach with full backups and validation at each step.
1. Document current state
First, verify no feature gates are currently configured:
|
|
All nodes returned empty—no feature gates configured.
2. Backup existing configs before changes
|
|
3. Generate new configs and compare
|
|
Here’s what the diffs look like in VS Code:
Kubelet patch – adds extraConfig.featureGates.ImageVolume: true:

API server patch – adds extraArgs.feature-gates: ImageVolume=true:

4. Dry-run first node
Test the config without applying to catch any errors:
|
|
The dry-run output showed exactly what would change:
|
|
5. Apply one node at a time
Start with the first node, wait for it to return to Ready, then proceed:
|
|
6. Apply to remaining nodes
Only after stanton-01 is confirmed healthy:
|
|
All three nodes applied the config without requiring a reboot—Talos intelligently determines whether kubelet/API server changes need a full reboot or just a service restart.
Validating the feature works
With the feature gate enabled, I force-reconciled the qbittorrent helmrelease (the --force flag ensures Helm reapplies the deployment even if the chart version hasn’t changed):
|
|
Once the pod came up, I verified the image volume was mounted and the binary was accessible:
|
|
Output shows the entire OCI image filesystem mounted read-only:
|
|
And verify the binary is executable:
|
|
|
|
The ImageVolume feature is working—the qbrr binary is available at /qbrr/qbrr without any init containers or volume copying.
Lesson learned: type: image persistence is a cleaner pattern for shipping binaries or config alongside your main container. You avoid init containers that copy files around, and the volume is immutable. The feature gate requirement means it’s not for everyone, but on a homelab where you control the cluster config, it’s worth enabling.
Guardrails I’m putting in place
- Wipe before redeploying storage – running
blkdiscardandwipefsis now part of the Taskfiletalos:nukeflow so Ceph never trips on residual GPT headers again. - Namespace-scoped Flux Kustomize – large-scale reorganizations happen behind feature branches and are reconciled one namespace at a time instead of flipping the entire cluster at once.
- Talos factory IDs in version control – keeping the Talos schematic IDs and Thunderbolt routes in
talconfig.yamlmeant the reinstall was deterministic. Future upgrades will keep those comments updated so I always know what ISO to pull. - Document the scary steps – posts like this become my runbook. The next time Talos needs to be rebuilt I can follow the exact steps—Ubuntu live boot,
blkdiscard,task talos:bootstrap,task flux:bootstrap—without searching through old Discord threads.
Update 2025-11-24: Overseerr Connectivity Issues After Gateway API Migration
After completing the Envoy Gateway migration, I discovered that Overseerr couldn’t communicate with any of the sonarr/radarr/plex instances. The logs showed consistent timeout errors:
|
|
The Root Cause
Before the migration to Gateway API routes, Overseerr was configured to use external domain names (e.g., sonarr.${SECRET_DOMAIN}, radarr-uhd.${SECRET_DOMAIN}). These domains were resolving via k8s-gateway DNS to the envoy-internal LoadBalancer IP 10.90.3.202.
The problem? Pods cannot reach LoadBalancer IPs directly when using Cilium’s socketLB in certain configurations. While I had enabled socketLB to fix the hairpin NAT issue for external services, it wasn’t working for all pod-to-LoadBalancer scenarios.
Testing revealed:
- ✅ Direct cluster DNS (
sonarr.downloads.svc.cluster.local:80) - WORKS - ✅ ClusterIP access (
10.96.251.188:80) - WORKS - ❌ LoadBalancer IP (
10.90.3.202:80) - TIMES OUT - ❌ External domains (resolve to LoadBalancer IP) - FAILS
The Solution
The fix is simple: use internal cluster DNS names instead of external domains. Since all the *arr services run in the downloads namespace and Overseerr runs in entertainment, I needed to update the Overseerr configuration to use fully-qualified cluster DNS names.
Update Overseerr (Settings → Services) with these internal service URLs:
Sonarr instances:
- Sonarr (Default):
http://sonarr.downloads.svc.cluster.localport80 - Sonarr Horror:
http://sonarr.downloads.svc.cluster.localport80 - Sonarr UHD (Default 4K):
http://sonarr-uhd.downloads.svc.cluster.localport80 - Sonarr Foreign:
http://sonarr-foreign.downloads.svc.cluster.localport80
Radarr instances:
- Radarr (Default):
http://radarr.downloads.svc.cluster.localport80 - Radarr UHD (Default 4K):
http://radarr-uhd.downloads.svc.cluster.localport80
** Plex instances:**
- Plex:
http://plex.entertainment.svc.cluster.localport80 - Tautulli:
http://tautulli.entertainment.svc.cluster.localport80
All should have SSL set to false since internal cluster traffic doesn’t need TLS termination.
I also had to fix the link to Plex inside Tautulli by setting it to
- Plex:
plex.entertainment.svc.cluster.localport32400
Why This Happened
The original configuration worked with ingress-nginx because it ran with hostNetwork: true, meaning pods accessed services through the host’s network stack and never hit the LoadBalancer service abstraction. Envoy Gateway deploys as regular pods without hostNetwork, so any attempt to reach a LoadBalancer IP from inside the cluster goes through the LoadBalancer service.
While Cilium’s socketLB is supposed to handle pod-to-LoadBalancer connectivity, the most reliable pattern is to use cluster DNS for internal service-to-service communication. LoadBalancer IPs should only be used for external ingress traffic.
Lesson learned: After migrating from ingress-nginx to Gateway API, audit all application configurations that reference external domain names for internal services. If both the client and server are in-cluster, use cluster DNS (<service>.<namespace>.svc.cluster.local) instead of external domains that resolve to LoadBalancer IPs.