“High availability for LLMs doesn’t need to be hard. Just give them a shared brain and a quiet place to think.”
Intro
This is the continuation of my open source LLM deployment journey. In Part 2, I got Open-WebUI up and running with a connection to OpenAI and some solid OIDC-based auth.
Now it’s time to actually host my own models — enter Ollama.
Why Ollama?
Ollama is a great backend for running open-source models like Mistral, DeepSeek Coder, TinyLLaMA, and many others. It offers:
- A clean CLI and API
- OpenAI-compatible endpoints
- Easy Docker-based deployment
- Excellent model ecosystem
…but it also comes with a few quirks — especially when trying to run it in Kubernetes. Let’s dive into how I set it up and what I learned.
Goals
- Deploy Ollama in Kubernetes
- Support High Availability across 3 nodes
- Share model and config volumes across pods
- Preload models to avoid UI pulls (at first)
- Integrate with Open-WebUI
Why I chose a DaemonSet
Most guides suggest deploying Ollama as a single Deployment, but I had other plans. I wanted Ollama to:
- Be available on each node
- Share model storage (so models don’t redownload per pod)
- Provide resilience — if one node goes down, the others keep serving
For that reason, I rolled it out as a DaemonSet, with a shared RWX volume for models and config. That means each node hosts its own Ollama pod, but they all read/write to the same /models and /root/.ollama paths.
This was critical because:
- Downloads happen once
- Config/state persists
- Open-WebUI can talk to any node
Storage Setup
I used a CephFS-backed PVC with ReadWriteMany access mode to share data across pods. Here’s the relevant snippet:
|
|
If you’re running the bjw-s app-template Helm chart, that’s how you wire volumes into the containers cleanly.
What about model preloading?
I initially tried to preload models using an initContainer, but Ollama’s CLI expects a running server in the background for ollama pull to work. That meant the init container crashed trying to pull models before the server was up.
I then considered a Kubernetes Job that spun up a temporary ollama serve, pulled the models, and exited, but in the end — I decided to keep it simple.
Pulling Models via UI
Instead of declarative model pulls, I now:
-
Browse to you Open-WebUI URL
-
Log in as admin
-
Select your avatar in the top right and click Admin Panel
-
In the top left menu click Settings
-
Then in the left menu click Models
Here you will see all your OpenAI/ChatGPT models if you followed that step from my previous post -
Click on the download icon in the top right
-
Next, look at ollamas supported models. found here.
- Search for each model that you want, click on it, then tags drop down and click View All
- make a nodel of the model and tag you want:
- tinyllama:1.1b
- mistral:7b-instruct-q4_0
- deepseek-coder:6.7b
-
Click the download Icon next to where you pasted the model:tag
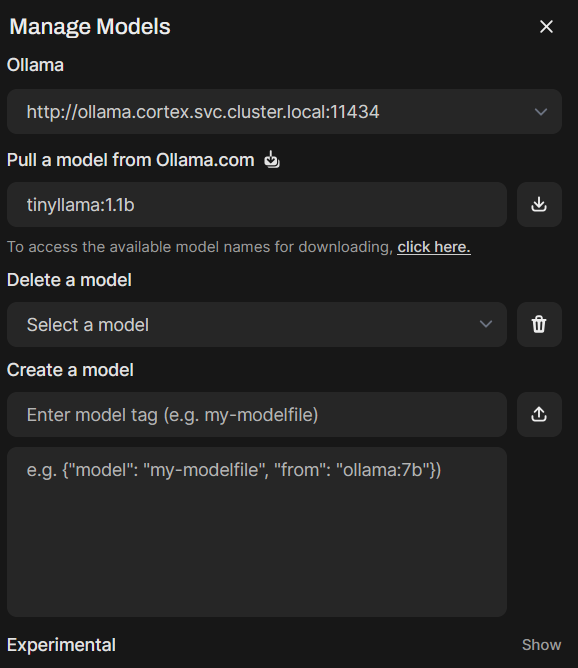
-
You will see the model begin to download and will see topups in the top right about it verifying the SHA
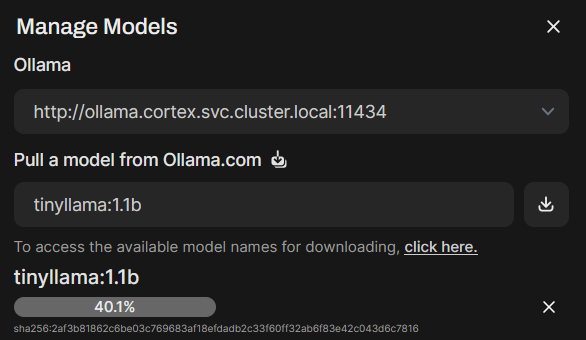
-
After that is complete, refresh the admin page and click models from the left manu again and scroll down through the list to see your new model
-
Repeat this process for your other models
-
Lets verify, from your Terminal run the following command which will grab the first ollama container and report the models:
kubectl -n cortex exec -it $(kubectl -n cortex get pods -l app.kubernetes.io/name=ollama -o jsonpath='{.items[0].metadata.name}') -- ollama list -
Remember, if you want to change your default model, click the cog next to the download icon you clicked earlier. here you can reorder the model list and choose your default.
Note
Because all my Ollama pods share the same /models volume, once a model is downloaded, it becomes instantly available to all nodes.
Gotchas
- You can’t use
ollama pullunless the server is running. Init containers don’t work unless you do a background process trick. - Use a DaemonSet only if you have shared storage. Otherwise you’ll redownload the same models three times.
- Open-WebUI doesn’t preload models declaratively. Use the admin UI.
- Text Only These models are not able to read images an interpert text.
My Current State
You can see the full setup in my home-ops repo here:
The result: I now have a high-availability Ollama setup across 3 nodes, talking to a clean OIDC-protected Open-WebUI front-end, and serving both OpenAI models and my own local ones — no cloud dependencies required.
Next Steps
I’m watching PR #6729 on the Ollama repo closely. When it lands, I plan to test distributed inference across all nodes — allowing parallel execution and true multi-node load balancing.
I’m also keeping an eye on vLLM, which is designed for blazing-fast inference and serves models with lower latency, dynamic batching, and high throughput — ideal for production-level performance. It’s more complex to integrate and resource-hungry, but I’m planning to explore it for my homelab in a future post.
Stay tuned for Part 4 👀